Summary
- We used AI to build an unofficial implementation of GIST, then benchmarked it on T&S datasets.
- On hate speech and offensive content datasets, GIST matched or beat classifiers trained on 5x more randomly-sampled data.
- Diversity-first sampling helps T&S teams do more with smaller labeling budgets, especially when harmful content is rare or takes many forms.
- We've open-sourced our GIST implementation. You'll find a link to that at the end.
Why Data Sampling Matters in Trust and Safety
Trust & Safety teams deal with messy data and limited labeling budgets. We wanted a way to use fewer training examples without losing the variety of content we need to learn from. GIST is a sampling method that prioritizes diversity: it picks examples that are different from each other, rather than grabbing whatever comes first. For T&S work, where harmful content can take many forms and evolve quickly, keeping that variety makes a big difference.
There's also a very practical problem we see in moderation queues: sometimes a single spam campaign or coordinated attack floods the queue with near-identical content. If 90% of what you're labeling is basically the same, having to manually review all of it is a waste of time. A diversity-focused sampler keeps a few representative examples from that flood while freeing up labeler time for the genuinely new and different content that needs attention.
Understanding GIST Through a Practical Example
To illustrate, let's generate synthetic data that mimics a typical moderation queue. The dataset contains 500 posts distributed across 5 topic clusters:
Topic Cluster Distribution
Example Posts Per Topic Cluster
The GoFundMe spam makes up 60% of the dataset. Let's compare random sampling and GIST:
Random Sample Set
Random sampling five posts from this dataset only covers 2 of 5 clusters:
GIST Sample Set
GIST sampling five posts covers all five clusters:
With labeled data, stratified sampling could achieve the same result. But GIST had no labels – it didn't know which posts were spam versus discussion. Each selected point "covers" the nearby data it represents: picking another GoFundMe message adds nothing since that topic is already covered, while picking the first Star Wars post covers a whole new region. GIST finds this diversity automatically.
-----
The next sections cover how we built the library, how we benchmarked it on T&S datasets, and what we learned. If you'd rather skip to the practical takeaways, jump to Practical Tips or What This Means for Trust & Safety Teams.
-----
Building an Open-Sourced GIST Tool
We used AI coding agents to go from a research paper to a working, tested library with real-world benchmarks in a few sessions. The AI summarized the paper, drafted the API, proposed tests, and iterated on feedback. The human role was deciding what mattered, validating behavior, and pushing for simplicity. That iteration speed changes what's practical – ideas that would have taken weeks to prototype can now be explored in an afternoon.
The first version worked but slowed down badly above 5k rows. A simplification pass cut the codebase by ~40% and exposed the hot spots. The main fixes were batching gains for sparse facility location, switching to CSC for column access, and improving gamma estimation. The approximate mode now delivers 10x+ speedup for n > 3k while staying at 99%+ quality vs exact, with significant memory savings.
Workflow learnings:
- Feed the agent rich context upfront. Give it the paper, existing code, and constraints. Context quality determines output quality.
- Define success criteria upfront. Let the agent run tests and benchmarks.
- Ask for simplification and cleanup early. It exposes duplicate paths and hot spots.
- Cycle between building and cleaning. Add features or fix bugs, then ask the agent to simplify and clean up. Repeat.
- Tell it not to worry about backwards compatibility. During initial development, this frees the agent to make better refactors.
- Review diffs. Once things are working, focus on the changes.
Note: The agent space is evolving fast – what worked a few weeks ago has already changed as the tools evolve. Take these learnings as a snapshot, some of these workflow tips will likely be outdated soon.
Benchmarking GIST for Trust and Safety
We benchmarked GIST on public content moderation datasets, training classifiers on samples selected by each method and comparing performance.
Setup
- Datasets:
tweet_eval/hate,tweet_eval/offensive,sms_spam(Hugging Face) - Embeddings:
sentence-transformers/all-MiniLM-L6-v2, L2-normalized - Metric: ROC-AUC on a held-out test set (higher is better)
- Sampling Budgets: 2%, 5%, 10% of training data
- Methods: random (uniform sample), stratified (class-proportional sample, labels required), GIST, and stratify-then-GIST (run GIST within each class)
- Data size: 5,000 rows; 80/20 train/test split; mean +/- std over 3 seeds
- Classifier: benchmarks use sentence embeddings and a simple linear classifier
Dataset notes
tweet_eval/hate: short tweets labeled for hate speech (subtle language, low prevalence).tweet_eval/offensive: offensive language labels with more ambiguous boundaries than hate.sms_spam: short SMS messages with a clearer spam/non-spam boundary.
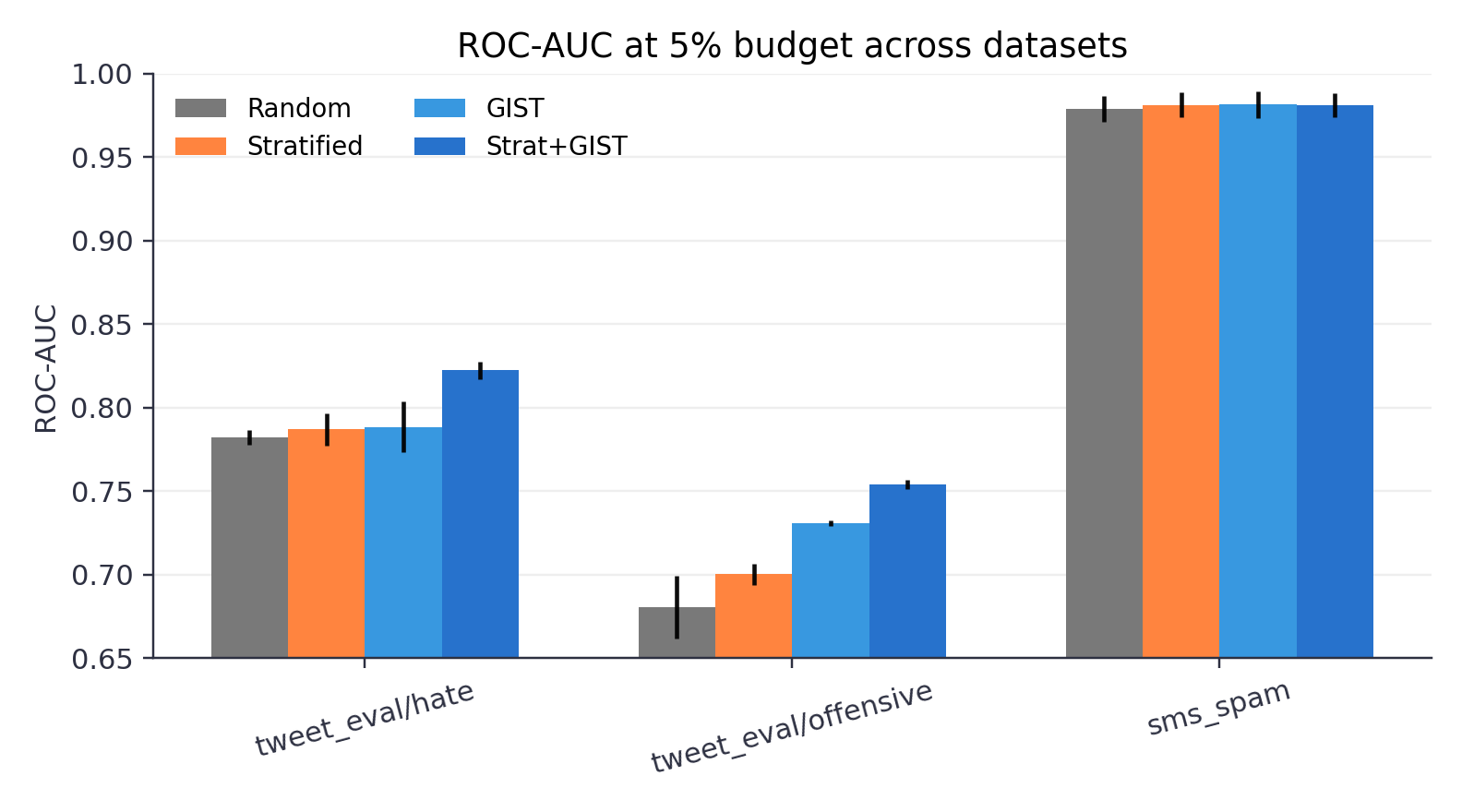
Results (mean +/- std ROC-AUC)
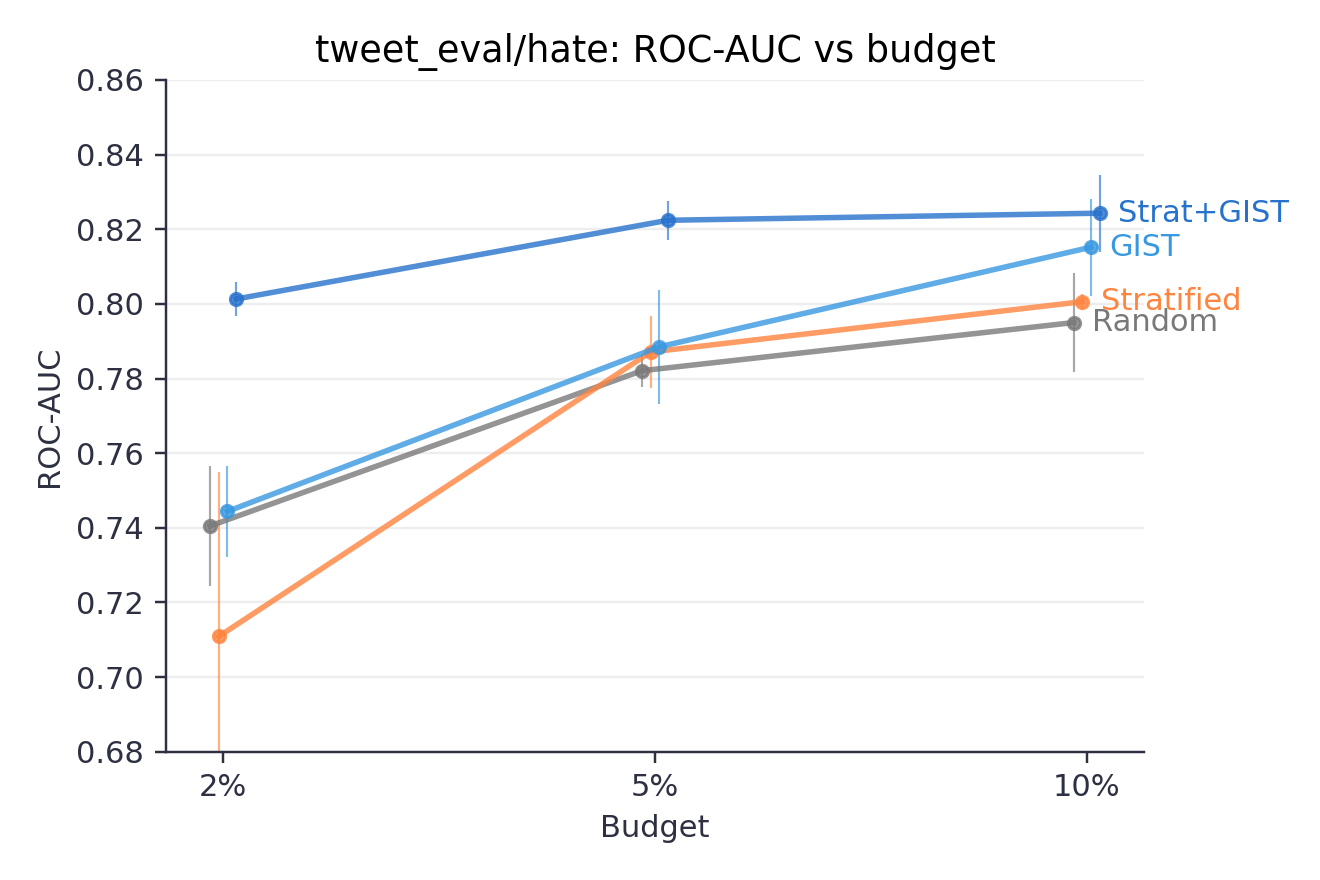
tweet_eval/hate
tweet_eval/offensive
sms_spam
What We See
sms_spam: clear spam signals mean all methods hit near-ceiling performance, leaving little room for diversity to help.tweet_eval/hateshows the clearest benefit from diversity plus class balance; stratify-then-GIST preserves minority class coverage while diversifying within each class.tweet_eval/offensive: fuzzier label boundaries and more varied language mean GIST helps by covering a wider range of usage patterns.
Generally, GIST's advantage is largest at smaller budgets and narrows as budget increases – consistent with diminishing returns once the main clusters are covered.
Practical Tips
Where GIST works well
- Start with dense numeric data. If you have text or other non-numeric data, use normalized embeddings and a cosine distance.
- If your labels are imbalanced, stratify first, then apply GIST inside each class.
- Compare against other sampling methods. Depending on the dataset, GIST may or may not be the best method.
Where GIST might not work well
- Sparse tabular data with many categorical or one-hot features, where distances are noisy or dominated by sparsity.
- Label boundaries that do not align with geometry, e.g., when the true signal is a rare feature rather than a broad semantic cluster.
- Tiny budgets on highly imbalanced datasets, where diversity-first selection can under-sample the minority class.
- Non-metric or ad-hoc distance functions that do not reflect meaningful similarity.
- Heavily missing or poorly normalized features, which can distort distance calculations.
A concrete example: one-hot encoded tabular data
Here's an example where GIST doesn't help. We ran it on the Adult Census dataset – categorical features (workclass, education, occupation, etc.) one-hot encoded into binary columns with high sparsity (92% of the values are 0). We trained a logistic regression classifier on subsets selected by each method and measured ROC-AUC:
GIST provides no advantage here, despite doing more computation.
GIST optimizes over pairwise distances, so it only helps when nearby points are meaningfully similar. For sparse one-hot data, distances don't carry that signal – a spot check shows that nearest neighbors share the same class only 74.3% of the time, which doesn't beat the 75.4% baseline. Without meaningful distances, GIST can't outperform simpler approaches.
What This Means for Trust & Safety Teams
What does this look like in practice?
Do more with smaller labeling budgets. Our benchmarks show that on hate speech data, GIST with class balancing at a 2% sampling budget (80 examples) achieves an AUC of 0.801 – outperforming random sampling at a 10% budget (400 examples), which only reaches 0.795. That's roughly 5x fewer labeled examples for equal or better classifier performance. For a team labeling thousands of items per day, that's real time and money saved.
Surface rare and emerging threats faster. Imagine a platform sees a new type of scam spreading through AI-generated images, but the moderation queue is flooded with the same high-volume spam campaign. Random sampling keeps pulling variations of the same spam. GIST, by design, surfaces the unusual, low-frequency content that looks different from everything else – the kind of emerging threat that might otherwise go unnoticed for days until it's already widespread.
Build better classifiers from day one. When you're training a new content classifier – say, for a policy area you've never modeled before – the examples you start with shape everything downstream. A diversity-optimized training set covers more of the content landscape from the start, reducing the need for expensive re-labeling cycles as you discover gaps.
Try It Yourself
We've open-sourced our GIST implementation – give it a try!
GitHub: https://github.com/musubi-labs/gist-sampling
References
- Google Research blogpost: https://research.google/blog/introducing-gist-the-next-stage-in-smart-sampling
- Google Research paper: https://arxiv.org/abs/2405.18754