
LLM content moderation is the use of large language models to detect, classify, and action policy-violating content at scale. Unlike traditional ML classifiers, LLMs can interpret nuanced context, enforce complex policies in natural language, and operate across 80+ languages without separate per-language models. This guide covers what T&S teams need to know to implement, evaluate, and operate LLM-based moderation in production.
Generative AI (specifically Large Language Models, or LLMs) can help scale Trust & Safety operations, increase decision accuracy, and free up human moderators to do more specialized and strategic work. It can also reduce exposure of moderators and users to disturbing and traumatic content.
But, as any Trust & Safety leader who has implemented new technology knows, it's not that simple. The gap between promise and reality is filled with complex, real-world problems, and it can be hard to know how to get started, especially because the world of AI is moving so fast.
This guide covers the practical realities: how to choose between model types, measure results quickly and reliably, set the right metrics, handle failures, and keep humans meaningfully in the loop. Whether you're just starting to explore LLMs or refining an existing system, you'll learn what works, what doesn't, how to avoid the most common pitfalls, and how to build systems where both moderators and AI are set up for success.
LLM Model Selection for Content Moderation
Before talking about implementation, it's helpful to understand the landscape of LLM options available for content moderation.
- Foundational models are large, general-purpose LLMs like GPT-5 or Claude Opus that have been trained on massive datasets and can handle a wide variety of tasks. They typically support 80+ languages and can reason about complex, nuanced content in any number of scenarios. They're powerful but also can cost more to run and have higher latency (slower response times) than traditional fixed ML or smaller models (that said, costs are coming down rapidly, and they’re also significantly cheaper and faster than human moderation teams).
- Reasoning vs. non-reasoning models is another distinction. Some LLMs are designed to "think through" problems step-by-step, which can be valuable for complex policy decisions. Others provide faster, more direct responses. Reasoning models tend to be more expensive and slower, but better at handling edge cases.
- Custom small models are built for a specific use case. They're faster and cheaper to run than foundational models, but they may only support English or a handful of languages. They also require significant upfront investment to build and train, and can’t be used for tasks outside of their core use case.
- Fine-tuned models start with a foundational model but are further trained on your specific data and policies. This can improve performance for your particular use case, but it requires ongoing maintenance and may need to be redone when the base model is updated.
The choice between these options involves tradeoffs between cost, accuracy, language support, and maintenance burden. Many platforms use a layered approach: a fast, cheap model for initial filtering (high recall) and a more sophisticated model for nuanced decisions (high precision).
An advantage of AI technology is that it’s improving all the time, but it does require expertise and tools to test new models against each other and make cost and accuracy tradeoffs. It can be a technical challenge to integrate and manage ever-changing LLM models.
Infrastructure and Integration of LLMs
Integrating with every single foundational LLM provider (i.e. OpenAI, Anthropic, and Google) can be cumbersome and difficult, whereas if you choose just one, the sunk cost fallacy is real. Once you pinpoint the best LLM at the time and integrate, it's hard to move off it, even if another LLM comes out that is better. There's intense competition between providers, so new models are always coming out and improving. Different models may also be better for different policy areas. For example, one might excel at detecting hate speech while another handles nuanced fraud cases better.
☑️ Practical strategies for Infrastructure design
- Build flexibility into your infrastructure early. Use abstraction layers that let you swap models without rewriting your entire system. Set up A/B testing frameworks so you can evaluate new models on real traffic before fully committing. This flexibility becomes critical when you need to respond to failures or take advantage of improvements.
- Consider privacy concerns around sending sensitive user content to a third-party LLM. This may be solved by hosting on a private cloud. Keep in mind that private hosting will increase lock-in and increase your infrastructure costs, but it gives you control over data security and residency requirements that may be critical for compliance.
- Test your model’s safety guardrails. Different AI models have their own guardrails in place, especially around areas like child safety. If you're planning on using an LLM for content moderation, you may need to get permission to turn off these guardrails in order to properly label harmful content. This requires clear agreements with your vendor about what you're doing and why.
AI-Ready Team Structure and Skills
Implementing LLM-based moderation isn't just a technical project, it requires the right team and skills to succeed. The good news is that you can often upskill your existing team members rather than hiring entirely new roles.
A typical team structure might include policy experts who define and refine rules, prompt engineers who translate policies into effective LLM instructions, engineers who handle infrastructure and integration, and analysts who monitor metrics and identify issues. In smaller teams, these roles overlap. The key is making sure all the functions are covered.
☑️ Practical strategies for your team
The field moves incredibly fast. What your team learns today may be obsolete in six months as new models and techniques emerge. They need the capacity to stay current through industry events, research papers, and practitioner communities. Budget time for learning and experimentation.
- Policy experts can learn prompt engineering with the right training and practice. Many people find it intuitive once they understand the basics, because it's more about clear communication and structured thinking than deep technical knowledge. That said, prompt engineering can be a heavy lift if no one on your team is willing or able to learn. Some people take to it naturally, others struggle. Assess your team's interest and aptitude early.
- The question of who owns ongoing maintenance is critical. LLMs require continuous attention: monitoring metrics, updating prompts, evaluating new models, refreshing golden datasets. This can't be a side project for someone with a full-time policy role. You need dedicated ownership, whether that's a specialized role or a clear allocation of someone's time.
- Use Red Teams before new deployment. A Red Team’s job is to use adversarial techniques to identify potential risks to a system, such as biased outputs, misinformation, or system misuse. Before using LLMs to moderate, have a Red Team come up with as many examples as they can to try to get around the policy enforcement. Your Red Team can be made up of outside experts, but could also be a cross-functional internal team made up of Trust & Safety experts, cybersecurity team members, or even Employee Resource Groups.
For more on this, read our guide on building AI-read Trust & Safety teams.
Language Capabilities and Limitations of LLMs
Language support is one of the most significant considerations when choosing an LLM approach, and it's an area where the tradeoffs can be complex.
Large foundational models like GPT-5 or Claude can handle 80+ languages out of the box. This is remarkable and represents a huge leap forward from traditional ML classifiers, which often required building separate models for each language (and sometimes billing separately too). However, performance across these languages is far from equal. English and other high-resource languages like Spanish, French, and Mandarin see better accuracy than lower-resource languages like Swahili, Urdu, or indigenous languages.
☑️ Practical strategies for language coverage
- Imperfect moderation can be better than no moderation. Not many platforms are large enough to support human moderation teams that speak 80+ languages, and no out-of-the-box fixed ML model for moderation supports this many languages either. If your current moderation system only supports a small handful of languages, switching to LLM moderation will increase your language capabilities, even if the accuracy in Tagalog isn't as good as English.
- Quality disparities raise important equity concerns. Users who speak lower-resource languages may experience higher rates of both over-enforcement (content incorrectly removed) and under-enforcement (harmful content that stays up). This creates a tiered system where some communities are better protected than others. It's critical to be transparent about these limitations and invest in improving performance for underserved languages over time. Building in human-in-the-loop systems (like appeals flows) is critical.
- Custom small models present a critical tradeoff. Teams may build smaller, specialized models that only support English or a handful of languages. These can be cheaper to run and may outperform foundational models for specific types of content in those languages. But you lose the broad language coverage. If your platform is English-primary but growing internationally, you may need to choose between better performance now and broader coverage later.
The practical approach for many platforms is layered: use a multilingual foundational model for broad coverage, but supplement where needed. Test thoroughly across languages during development and don't assume that performance in English will translate to other languages.
Understanding and Addressing Bias in Content Moderation
AI bias manifests in various ways. Models might associate certain dialects or speech patterns with violations when they're actually benign cultural expression or reclaimed language. They might over-flag content from certain demographic groups while under-flagging similar content from others. Gender assumptions can creep in, for example a model might treat identical aggressive language differently depending on perceived gender of the speaker. Religious or cultural references might be misclassified as hate speech when they're actually in-group communication.
The impact of these biases isn't abstract. It means marginalized communities may face higher rates of content removal, account restrictions, and platform exclusion. Meanwhile, harmful content targeting those same communities might slip through. This creates a compounding problem where the people most vulnerable to online harm also face the most barriers to participation.
Bias in AI systems has multiple sources. Training data reflects existing societal biases— if the internet overrepresents certain viewpoints or underrepresents certain communities, models learn those patterns. Models can also learn incorrect shortcuts, such as associating a particular emoji with drugs just because drug seekers use it frequently, even though there are legitimate uses for it too.
It's worth noting that human moderation also has bias problems. Individual human reviewers bring their own cultural backgrounds, personal experiences, and unconscious biases. A reviewer's mood, fatigue level, or recent experiences can affect decisions in ways that are hard to predict or control.
ML experts increasingly argue that it's impossible for large language models to be completely free from bias, just as it's impossible for human reviewers to be completely unbiased. The realistic goal is to minimize bias, monitor for it continuously, and be transparent about limitations. A system that acknowledges and actively works to address bias is better than one that claims to be bias-free.
The best approach is to carefully test for bias, and layer your defenses. Use automated detection with awareness of its limitations. Write thorough and fair policies. Use few-shot examples to train the LLM. Route uncertain or sensitive cases to human review, but train those reviewers on bias awareness too. Build diverse teams (both the humans and the training data). Test rigorously across different groups. Listen to user feedback, especially from marginalized communities. And always, always keep measuring and improving.
☑️ Practical strategies for bias mitigation
AI bias can be systematically addressed. This is actually an advantage of automated systems. You can measure bias in models by evaluating performance separately for different demographic groups, languages, or content types. Red teaming with diverse perspectives can surface blind spots before deployment.
When, for example, you discover your model over-flags African American Vernacular English as threatening, you can add representative few-shot examples to your policy. This kind of systematic improvement is much harder with human review teams or fixed ML models.
- LLMs are steerable. This is one of their most powerful features for addressing bias. You can provide explicit policy instructions that override baseline model behavior. If your platform defines hate speech differently than the model's general training suggests, you can encode that specific definition in your prompts. You can give explicit guidance about cultural context: "Religious text quotations are not violations even if they contain violent imagery" or "AAVE dialect should not be flagged as low quality or threatening."
This steerability gives you more control over policy enforcement than you might have with a fixed ML model or human teams whose personal biases and interpretations vary, and whose ability to remember guidelines and directives is limited. A human reviewer's implicit bias might be hard to detect and correct. An LLM's bias can be directly addressed through prompt engineering, though you need to test thoroughly to ensure your instructions actually work as intended. - Continuous monitoring is essential. Bias issues may not be evident until a model is deployed and facing real-world content. Even after careful testing, you might discover edge cases or systematic problems. Set up alerts for performance disparities across different user groups. Track appeal rates and overturn rates by demographic factors when possible (while respecting privacy). Review samples of flagged and unflagged content regularly to spot patterns.
- When you find bias issues, treat them as high priority. Document what you found, how you're addressing it, and test the fix before deploying. Build feedback loops so that identified biases inform future model development and evaluation.
- When evaluating models, go beyond overall accuracy metrics. Break down performance by language, region, content type, and any demographic factors you can ethically measure. Look for disparities in false positive rates (over-enforcement) and false negative rates (under-enforcement) across groups. Some teams use fairness metrics like demographic parity (similar outcomes across groups) or equal opportunity (similar true positive rates across groups). The right fairness metric depends on your context and values. There's no universal standard. What matters is that you're actively measuring and addressing disparities rather than assuming equal performance.
For more on this, read our guide on understanding and addressing bias in content moderation.
Creating and Maintaining Golden Datasets for T&S
A golden dataset is one of the simplest and most versatile tools for moderation evaluation. It's a curated set of labeled examples that represents your "ground truth" - the answer key you can use to test anything against.
A great golden dataset is key to success with using LLMs for moderation. Without it, you have no reliable way to measure bias and performance, compare models, or identify drift. The effort you put into your evaluation dataset directly determines how well you can assess your model's performance. Once you have one, you can benchmark moderators, evaluate AI vendors, compare different models, or test whether changes you’ve made have improved your decisions.
However, there's cost and time involved in creating and maintaining a rock-solid golden dataset. It's difficult to collect, label, and keep a golden set up to date, but it's also one of the most important investments you can make.
☑️ Practical strategies for effective golden dataset management
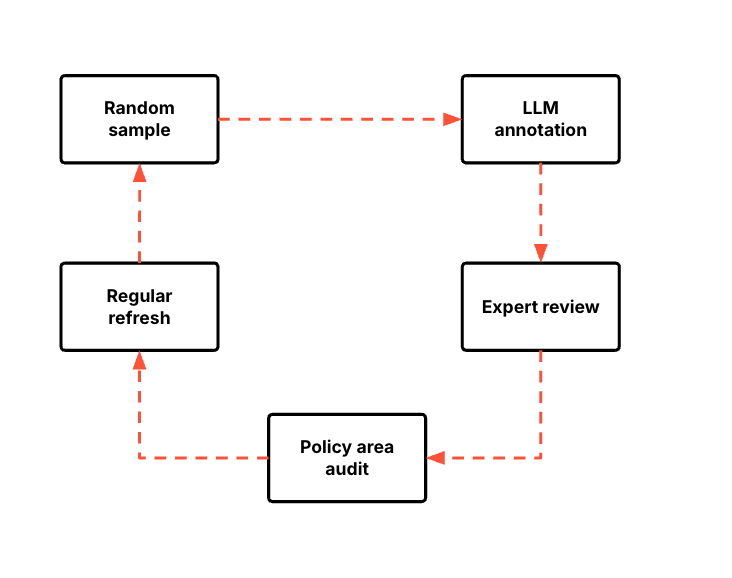
- Use a random sample of real user data from a specific time period. Aim for representativeness across content types, languages, and policy areas. Avoid the temptation to only sample "interesting" or borderline content. That can be fine to test for the most difficult cases, but you also need a realistic distribution that mirrors what your model will see in production. A good target is at least 100 examples per policy area, though more is better for rare violations.
- Use a reasoning LLM or LLM-as-a-judge to annotate the set, based on your policies. This can speed up initial labeling significantly, but treat these labels as a starting point, not ground truth. Always have humans review and correct the labels.
- Use policy experts to review and correct labels. Human expertise is irreplaceable for establishing the gold standard. Your most experienced moderators should be heavily involved in this process. Budget their time accordingly. This is high-value work that pays dividends in better model evaluation.
- Look for over- and under-sampling of specific areas. If you have 500 examples of spam but only 5 of harassment, your evaluation will be skewed and you won't catch failures in harassment detection until they're already affecting users. Rebalance as needed to ensure comprehensive coverage.
- Refresh your golden dataset regularly as policies evolve and new abuse patterns emerge. A golden dataset from six months ago might not reflect current threats. Set a cadence— quarterly updates work for many teams, more frequently if your policies are changing rapidly or you're seeing new types of abuse.
For more on this, read our guide to golden datasets.
Operationalizing LLM Content Moderation
Once you've dealt with integration and built a golden dataset, it's time to write your policy for the LLM to enforce. There are several ways to adapt an LLM to your specific moderation needs, each with different tradeoffs.
Prompt optimization involves carefully crafting the instructions and examples you provide to the LLM. Your policy experts can learn prompt engineering with some training. It's fast to iterate, requires no special infrastructure, and works with any LLM. The downside is that it can take quite a bit of training and experimentation to be able to write a good policy that an LLM can enforce consistently.
That said, LLMs can help with policy development itself. A technique called "LLM-as-a-judge" (where you use an LLM to evaluate content and compare its decisions to human expert judgments) can help identify policy gaps and ambiguities. You provide the LLM with your policy and a set of examples, have it make decisions, then review where it disagrees with human moderators. These discrepancies highlight where your policy needs more clarity or examples.
Few-shot learning is a form of prompt engineering where you include a handful of examples in your prompt to guide the model's behavior. This can dramatically improve performance for specific edge cases or policy areas. The challenge is choosing which examples to include and managing prompt length.
Fine-tuning involves actually retraining the model on your specific dataset. This can yield the best performance but requires ML expertise, significant compute resources, and ongoing maintenance. When the base model is updated, you may need to re-fine-tune. Fine-tuning also makes it harder to switch between models, because you're more locked into your choice.
Most teams start with prompt optimization and few-shot learning. These techniques can get you 80-90% of the way there with much less overhead. Fine-tuning may make sense when you have very high volume and very stable policies.
☑️ Practical strategies for effective policy implementation
- Define clear policy objectives first. Ensure your policy documentation clearly states what content is and isn't allowed on your platform. The more specific you can be about edge cases and gray areas, the better your AI implementation will perform. Vague policies lead to inconsistent enforcement, regardless of the technology used.
- Start with simple, high-confidence policies. Begin your LLM moderation journey with clear-cut violations that are easier to detect reliably, such as explicit threats, certain types of spam, or clear hate speech. As you gain experience and confidence in your system, you can expand to more nuanced policy areas.
- Test new policies in a sandbox environment. Before deploying a new policy enforcement mechanism to production, run it against your golden dataset and additional test data. Compare its decisions to your existing moderation system and analyze discrepancies. This helps identify potential issues before they affect users.
- Document your reasoning process. When defining policies for LLMs to enforce, explicitly document the reasoning process an LLM-moderator should follow. Breaking down complex decisions into steps helps LLMs follow your policy more consistently and makes it easier to diagnose when things go wrong.
Designing Human-in-the-Loop Systems For Trust & Safety
Everyone agrees about the necessity of human oversight... but how do you actually do that in practice? First, let's address a common misconception: human review isn't inherently better than automated review. There's public distrust of AI moderation and an assumption that humans are always more accurate, but the reality is more nuanced. Human review can have significant limitations, especially the outsourced, high-volume review that most platforms rely on. Reviewers may lack context, have varying levels of training, bring their own biases, and struggle with consistency across thousands of daily decisions.
The goal isn't to replace humans with AI or vice versa. It's to build a system where each does what it does best:
- AI excels at speed, consistency, and pattern recognition across massive scale.
- Humans excel at nuance, cultural context, and adapting to novel situations— especially when they’re given enough time, training, and autonomy.
The key is designing your human-in-the-loop process so that human reviewers are empowered to do high-value work.
One critical risk is overreliance on automation. When AI systems are sophisticated, there's a temptation for human reviewers to become passive, and automatically approve whatever the AI suggests without critical evaluation. This is called automation bias, and it defeats the purpose of human oversight. Your human reviewers need to understand how AI systems work, what their limitations are, and feel empowered to disagree with AI recommendations. Training your team on AI capabilities and failure modes is as important as training them on policies. If your "humans in the loop" are just button-pushers, you've lost the value they bring.
☑️ Practical strategies for effective human oversight
- Spot-check your model using a golden dataset. Look for model drift (when performance degrades over time because your real-world data changes from what it was trained on) by regularly evaluating your model against a representative dataset that covers all policy areas. This helps you catch performance issues before they become a widespread problem. Set up a regular schedule for these checks (for example, weekly for new models, monthly for established ones). Your golden dataset should be treated as ground truth, so invest in making it comprehensive and accurate based on what your platform looks like right now.
- Randomly sample recent decisions with skilled human annotation/ QA. Don't just look at appeals or user reports. Pull random samples of automated decisions to understand how your model is performing on typical content, not just edge cases. This gives you a realistic view of day-to-day accuracy and helps you spot systematic issues that users might not be appealing.
- Proactively red team and test, especially if your policies aren't built out. Before deployment, stress-test your models with adversarial examples and edge cases. Get creative and think like someone trying to evade detection. Test across languages, dialects, and cultural contexts to identify blind spots early.
- Use moderators for high-stakes appeals and update policies based on what you learn. When users challenge automated decisions, route these to experienced moderators. These appeals often surface important policy ambiguities or model failures that can inform your next policy update or fine-tuning strategy. Patterns in successful appeals tell you where your system is weakest.
- Send certain categories or severities to human teams. Establish clear thresholds for when content requires human judgment. High-severity violations, especially those involving potential harm to minors or imminent violence, should always involve human oversight, for example.
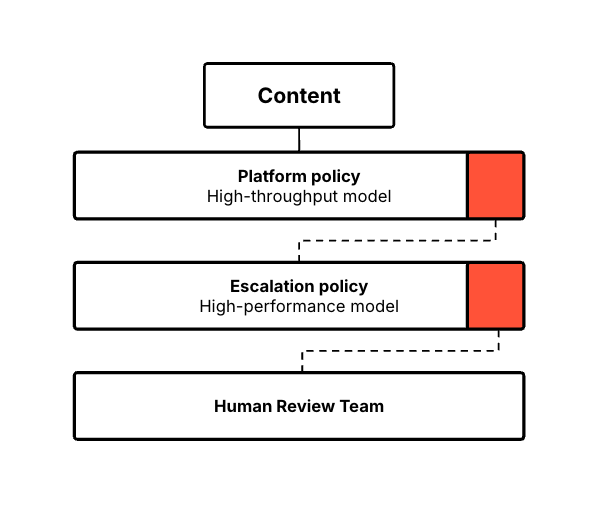
Measuring Success of LLM Moderation Systems
You can't improve what you don't measure. Setting up the right metrics framework is essential to understanding whether your LLM-based moderation is working and where it needs improvement.
- Precision measures the accuracy of your positive predictions. When your model says content violates policy, how often is it right? High precision means fewer false positives, and less content incorrectly removed. This matters for user trust and appeals volume.Calculate it as: true positives / (true positives + false positives).
- Recall measures completeness. Of all the content that actually violates policy, what percentage does your model catch? High recall means fewer false negatives, and less harmful content slipping through. This matters for platform safety and regulatory compliance.Calculate it as: true positives / (true positives + false negatives).
- F1 score combines precision and recall into a single metric. It's useful for comparing different models or approaches, especially when you're trying to balance the tradeoff between false positives and false negatives. An F1 score closer to 1.0 is better.
- User appeal rate is the percentage of automated actions that users appeal. A sudden spike suggests your model may be over-removing content. Track this separately by policy area and language. Appeals may be higher in some areas than others, which tells you where to focus improvement efforts.
- Appeal overturn rate measures how often appeals succeed. If 50% of appeals are overturned, your model has a serious accuracy problem. If only 2% are overturned, your appeals process might be too strict.
- Time-to-enforcement tracks how quickly violative content is detected and actioned after being posted. Faster is generally better, especially for high-severity content like CSAM or imminent threats. LLMs can dramatically reduce time-to-enforcement compared to human-only moderation.
Coverage by language and policy area helps you understand where your system is working and where it's struggling. Break down precision and recall by language to identify equity gaps. Track coverage by policy type to find areas that need more training data or policy refinement.
☑️ Practical strategies for measuring success
- Don't rely on a single metric. A model with 95% precision but 50% recall is catching violations accurately but missing half of them. Different policy areas will need different strategies, as well. For CSAM, you might prioritize recall even if it means more false positives. For political speech during elections, you might prioritize precision to avoid over-removal. Set different thresholds for different policy areas based on the relative costs of false positives vs. false negatives.
- Review metrics regularly. For example: weekly for new systems, monthly for mature ones, and dig in when metrics move unexpectedly. Your metrics framework should help you make confident decisions about when to adjust prompts, switch models, or escalate issues.
Monitoring, Failure Modes, and Incident Response
Even the best systems fail sometimes. What matters is how quickly you detect failures and how effectively you respond.
Continuous monitoring is non-negotiable. Monitor not just overall metrics but breakdowns by policy area, language, and content type. A model might work well overall but fail for specific edge cases.
Common failure modes to watch for include model drift (performance degrading over time as content patterns change), sudden changes in user behavior (new slang, memes, or evasion tactics), and upstream issues (your LLM provider having an outage or updating their model without warning). Each requires a different response.
☑️ Practical strategies for monitoring and response
- Have backup systems in place. If your primary LLM provider goes down, what happens? Do you have a secondary provider you can quickly switch to? Your backup strategy depends on your risk tolerance. Some platforms automatically fail over to a secondary model, accepting lower accuracy as the cost of staying operational. Others route everything to human review during outages, which is safer but expensive and slow. Still others have a hybrid approach: critical policy areas (CSAM, imminent threats) go to humans, while lower-severity content goes to a backup model. Document your strategy and test it regularly.
- Incident response procedures should cover both technical failures and policy failures. Technical failures are straightforward: model down, roll back to backup, notify stakeholders. Policy failures are trickier: model systematically misclassifying content, sudden surge in false positives, or community backlash to enforcement decisions. Have a clear escalation path, designated decision-makers, and communication templates ready.
- Continuous testing and model evaluation is essential in a fast-moving field. New LLMs are released constantly, and yesterday's best option might be outperformed next month. Set up a testing system that lets you evaluate new models against your golden dataset without disrupting production. Track which models work best for which policy areas. You might find that newer isn't always better, or that different models excel at different tasks.
Some teams run shadow deployments where new models process content in parallel with production systems but don't make actual enforcement decisions. This lets you evaluate real-world performance safely. Others do periodic "bake-offs" where several models compete on the same evaluation set. Find a cadence that matches your resources— quarterly evaluations might make sense for most teams, monthly for high-stakes areas.
Build feedback loops from incidents back into your system. When something goes wrong, update your golden dataset with examples from the incident. Refine your prompts or policies to address the gap. Use failures as opportunities to improve.
Deciding whether to Build vs. Buy Trust & Safety Solutions
One of the big questions teams face is whether to build their own moderation system or work with a vendor. There's no single right answer. It depends on your resources, scale, and strategic priorities.
Building basic capabilities yourself is absolutely possible, especially if you have engineering resources and want maximum control. You can start by integrating directly with LLM APIs, building your own evaluation frameworks, and designing custom prompts for your policies. This gives you flexibility and can work well for straightforward use cases or when you're still experimenting.
However, as your needs grow more complex, the maintenance burden increases significantly. You'll need to track new model releases, manage prompt versioning, build robust monitoring systems, handle failovers, and maintain evaluation datasets. The field moves fast— what works today may be outdated in months. Many teams find that what started as a simple integration quickly becomes a full-time job for multiple people.
Working with a specialized vendor and using a pre-built tool like Musubi can accelerate implementation and reduce ongoing maintenance. Good vendors bring expertise in prompt engineering, have already solved common technical challenges, and continuously evaluate new models as they're released. This lets your team focus on policy and strategy rather than infrastructure.
If you're interested, you can read our case studies for results and details from some of our customers.
The sweet spot for many platforms is a hybrid approach: build enough to understand the problem space and your requirements, then partner with vendors as your needs become more sophisticated or complex.
Common pitfalls to avoid (and their solutions)
Even experienced teams make mistakes when implementing LLM-based moderation. Here are the most common pitfalls we see, and how to avoid them.
Treating the golden dataset as a one-time project.
Teams build a great golden dataset, deploy their model, then never update it. New abuse patterns emerge, policies evolve, but the golden dataset stays static. This means metrics look good on old data but the model performs poorly on current threats.
The solution: set a regular cadence for golden dataset updates (quarterly at minimum, monthly for fast-moving platforms).
Not spending enough time creating golden sets that represent the problems you want to solve.
Random sampling sounds fair, but it often means you get lots of examples of common issues (spam, low-severity harassment) and only 1-2 examples of high-severity threats you most need to catch (CSAM, imminent violence, coordinated fraud). If your golden dataset doesn't adequately represent your highest-priority harms, you can't evaluate whether your model is actually catching them.
The solution: intentionally oversample rare but critical violation types.
Over-automating before you're ready.
Excitement about LLMs leads teams to remove human review too quickly. Without a baseline to compare against, you have no way to catch systematic failures.
The solution: run in shadow mode first, compare LLM decisions to human decisions, understand the discrepancies, and only then gradually increase automation as confidence grows.
Setting uniform thresholds across all policy areas.
Using the same precision/recall targets for spam and CSAM doesn't make sense. Not all violations are equal. Some need higher recall (catch everything, accept false positives), others need higher precision (only act when very confident).
The solution: thresholds should vary by severity, context, and potential harm of both false positives and false negatives.
Underestimating prompt maintenance.
Teams think prompts are "set it and forget it." But as abuse tactics evolve, prompts need constant refinement. Language shifts, new evasion techniques emerge, and yesterday's perfect prompt becomes tomorrow's blind spot.
The solution: assign clear ownership for ongoing prompt optimization, and understand that this is not a side project.
Not testing across languages before full deployment.
Teams assume English performance translates to other languages. They discover massive accuracy gaps only after user complaints roll in.
The solution: Always test in all supported languages during evaluation phase, not after launch. If you claim to support a language, you need to know how well your model actually performs in it.
Ignoring appeal patterns as an early warning system.
Teams treat appeals as noise rather than signal. They don't track which types of content are frequently appealed successfully or look for patterns in overturns. But appeals are often the first indicator of model drift or policy gaps.
The solution: monitor appeal rates and overturn rates by policy area and language, and investigate spikes immediately.
Building without redundancy or failover.
Teams rely on a single LLM provider with no backup plan. If that provider has an outage, everything goes unmoderated or gets blocked entirely.
The solution: Have a backup system so you can maintain operations during failures.
Copying human-written policies directly into prompts.
Policies written for human moderators have implicit context and cultural knowledge baked in. LLMs need explicit, structured instructions with examples. Directly copying policies into prompts results in poor performance and constant edge case failures.
The solution: Train, hire, or build tools for this skill. Understand that translation from human-readable to LLM-readable is real work that requires expertise.
Optimizing for the wrong metrics.
Teams chase high F1 scores without considering actual user impact. Metrics look great in dashboards, but users are frustrated by false positives and moderators are overwhelmed by bad routing.
The solution: Measure what matters: harm prevented, user trust, moderator efficiency, appeal burden, and community health.
Putting it all together
While AI presents a new set of problems (such as deepfakes and slop content), it also offers some of the most promising solutions we've seen. LLMs can potentially handle nuance better than traditional ML classifiers, adapt to new policies faster, and operate across more languages.
The real value of AI in Trust & Safety isn't to replace humans, but to empower them. It's about using automation to handle scale while freeing up human expertise for the high-stakes, nuanced, and emerging threats that only a person can handle. It also allows people's insights to be carried out at scale, rather than one-by-one as the traditional "factory model" of human content moderation does.
A well-designed system might work like this: LLMs handle the clear-cut cases automatically, routing borderline or high-severity cases to reasoning models and then to humans. The moderators focus on edge cases, appeals, and emerging threats, all while feeding their decisions back into the system as training data and policy refinement. This is work that's more engaging and less traumatic than reviewing endless queues of the worst content on the internet one-by-one.
If you're a T&S leader navigating this new landscape, know that you're not alone. The work is hard, but it's also more solvable than ever before. Start small, measure carefully, iterate quickly, and always keep humans in the loop.
-----
If you're thinking about adding AI to your content moderation strategy, or want to explore tools to make it easier, Musubi can help. Musubi's content moderation tooling lets policy experts easily write policies in any style they like, add examples, test against golden datasets, and compare policies and models side-by-side for performance, before seamlessly moving into production. If this is something you'd like to learn more about, let's chat.

Not sure which of these building blocks fits your platform?
That’s exactly the kind of thing we like to talk through, we can help you figure out where to start.