

Motivation
Policy-driven moderation using LLMs can enable Trust and Safety teams to scale their moderation capacity. Yet policies can be static documents, even as the content they moderate is constantly changing. A spam attack can have a clearly defined content signature today, but look completely different tomorrow. Traditional content classifiers look at content in isolation, but to catch abuse, we often have to find coordinated behavior.
What happens when bad actors pivot to a new behavior that content classifiers aren’t yet detecting? We prototyped a Content Radar to help answer that question.
Content Radar Overview
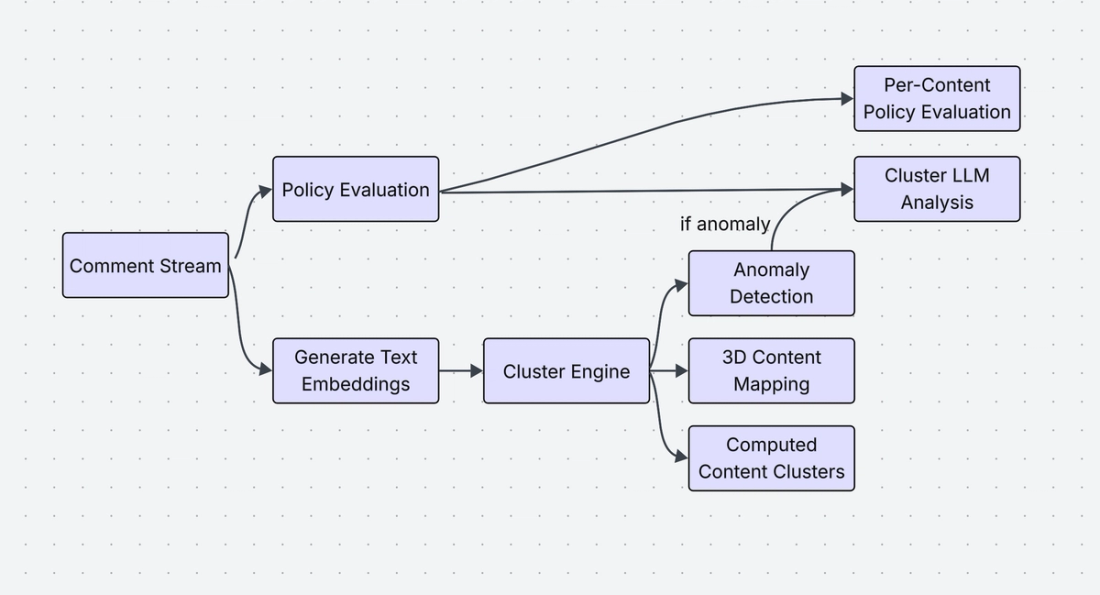
We built a Content Radar prototype that gives moderators an overview of dynamically changing content clusters on their platform. The radar sends out an alert if a content cluster is anomalous, and categorizes the content cluster according to a custom policy. The content radar proposes using a multi-tier policy evaluation approach where we:
- Evaluate each incoming piece of content according to a content moderation policy
- Evaluate each outlier content cluster according to a content cluster policy, that specifically detects coordinated behavior
This prototype was built on top of open source safeguard models and standard clustering techniques. The Content Radar is designed to help Trust and Safety teams identify anomalous coordinated behavior on their platform.
Data
We ran our initial evaluation on Google’s Civil Comments dataset, which has a collection of 1.8M comments on news articles. It’s an archive of comments on the Civil Comments platform, that was used as a plugin for news sites. To simulate real-time comments, the dataset was streamed in batches, and we then performed clustering and classification to each comment.
For testing purposes, we generated a set of borderline spam comments that when viewed in aggregate are clearly from a coordinated event because of common phrases and text patterns. These are mixed in with the civil comments dataset as comments as streamed into the content radar.
This setup simulates real-time monitoring of content as its generated on a platform. We aim to evaluate the feasibility of real-time content cluster detection and analysis.
Content Clustering
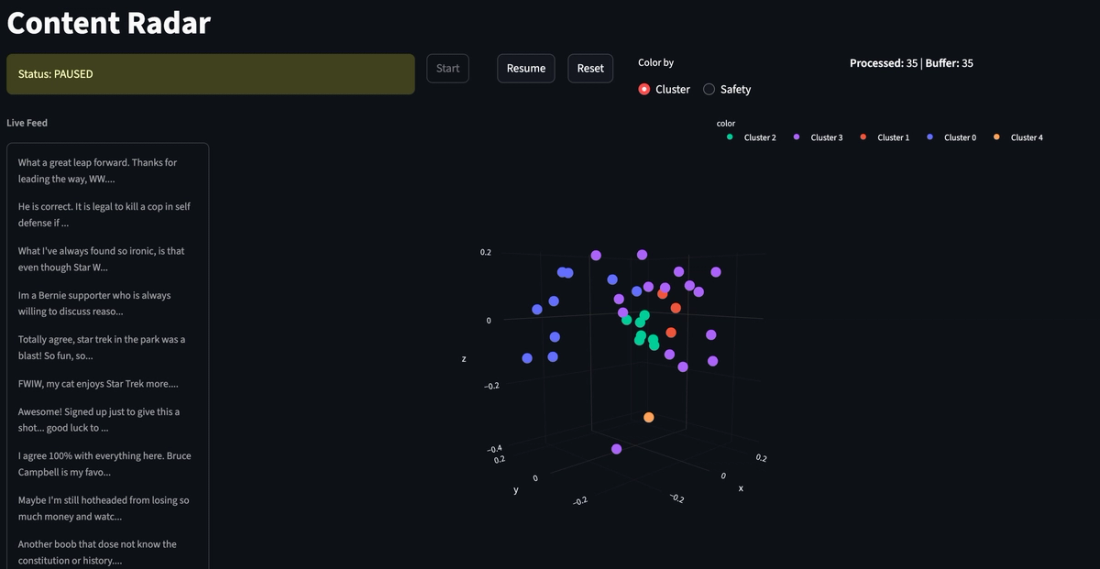
Comments are run through a Cluster Engine that computes a cluster assignment and a 3D coordinate for each comment. We then use the assignment and coordinate to map out the comments in a 3D visualization that helps discover anomalous content groups.
We compute content clusters as comments are streamed in. To compute clusters, we first generate a text-embedding of each comment. Comments are assigned to clusters by running mini-batch k-means on a sliding window of the last 100 comments.
Next up, we want to visualize the clusters in an interpretable way. We run principal component analysis to project the 768-dimensional text embeddings into 3 components. Then we can map each comment into a three dimensional space, where we have a spatial representation of each.
Multi-tier policy evaluation
As each comment comes in, we want to know:
- Does this comment violate our existing policy?
- When looking at a group of similar comments, is there a clear violation that our existing policy missed?
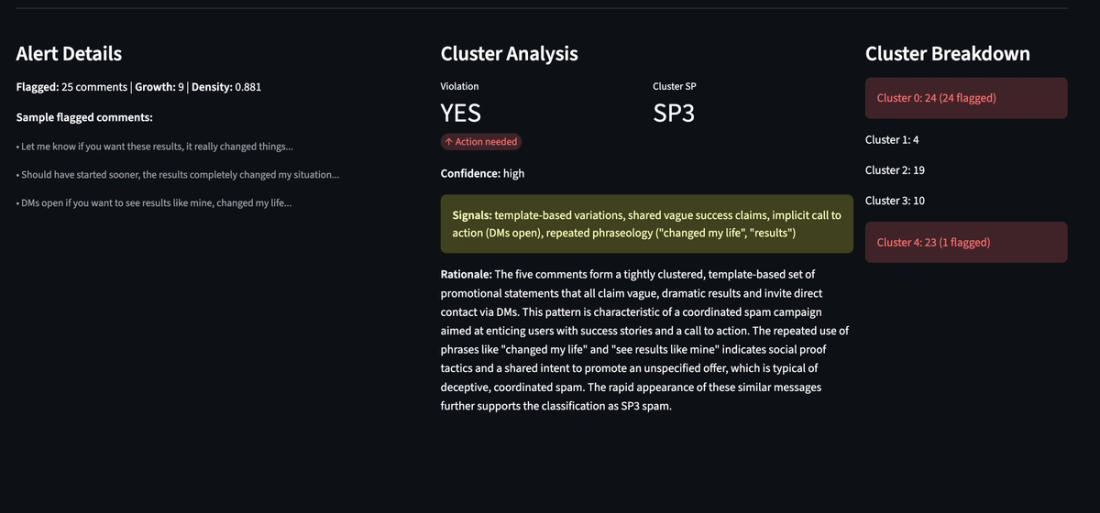
First, we pass in a generic spam-policy to the open source safeguard model to categorize each incoming comment as safe/unsafe based on its spam severity. Then we can use our content clusters to detect coordinated spam activity that our policy missed. For each anomalous cluster, we can send a sample of comments to a second content cluster policy that specifically looks for coordinated spam activity.
The idea is simply to find potential violations that may not be obvious when looking at an individual comment alone. With a multi-tier policy evaluation we still classify each incoming piece of content as safe/unsafe, but also use our clustering engine and a second-level of policy evaluation to detect coordinated behavior.
Results
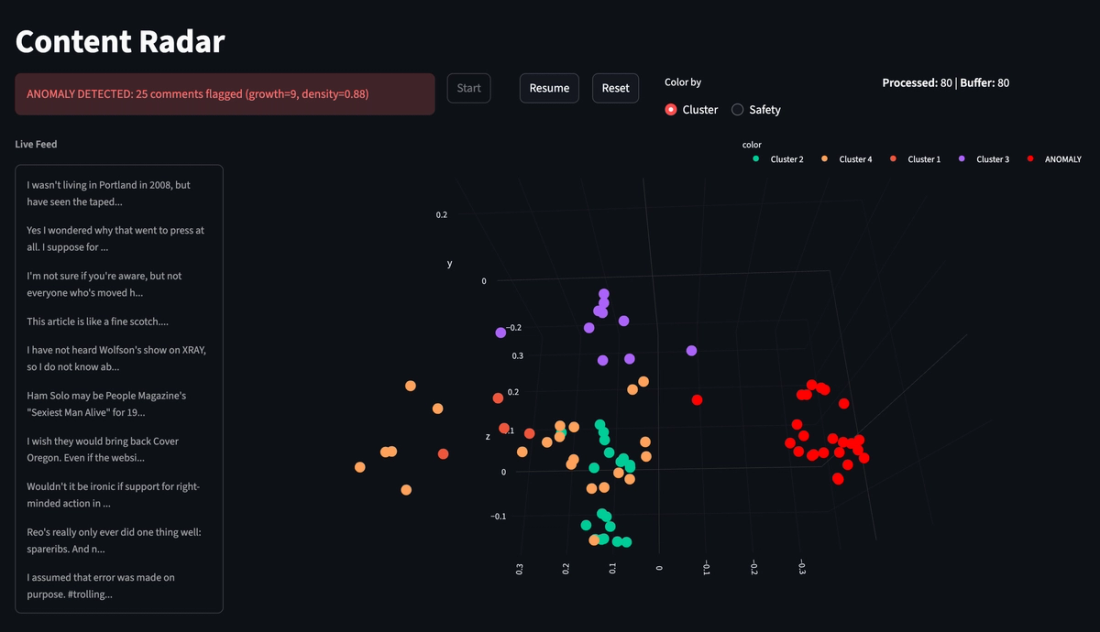
We streamed comments from our Dataset into Content Radar. Each comment was passed through the clustering engine and multi-tier policy evaluation. We used two policies for the multi-tier policy evaluation, an example prompt for spam detection for content classification, and a prompt explicitly looking for coordinated behavior as the second pass.
All comments were marked safe by our spam policy evaluation. Yet, our clustering engine and multi-step policy evaluation correctly identified the coordinated spam attack in our dataset. This shows a proof of concept for detecting bad actors with a distributed impact across a platform.
Next Steps
How can we use this approach to help Trust and Safety teams on internet-scale platforms? Some potential next steps include:
- Evaluate feasibility of real-time content clustering at scale. Perhaps batch clustering is sufficient.
- Is it feasible to find a stable alerting threshold or trigger? We found appropriate thresholds for this dataset, but we’d need to evaluate how anomaly detection and alerting would work in production.
- Evaluate effectiveness of multi-tier policy evaluation for content and content clusters
We hope this demonstrated a potential direction for AI moderation tooling. If you're exploring something similar, let's chat!